


1、校验组织架构错乱:com.qiyuesuo.org.department.DepartmentDao.wrongLrDepts
SELECT DISTINCT
*
FROM
DEPARTMENT
WHERE orgId = #{orgId} AND (
l IN (
SELECT DISTINCT d.l FROM DEPARTMENT d WHERE d.orgId = #{orgId} GROUP BY d.l HAVING COUNT(d.l) > 1
) OR
r IN (
SELECT DISTINCT d.r FROM DEPARTMENT d WHERE d.orgId = #{orgId} GROUP BY d.r HAVING COUNT(d.r) > 1
)
)Oracle环境下下,Department表总计数据量为:3800左右,本地每次执行,平均耗时大约在 4.8s 左右,页面上执行时间 5s 左右,SQL执行几乎占据了所有时间

由于Department表涉及的数据两并不大,也就是几千条而已,因此可以排除数据量导致的性能问题,在执行计划中可以看到主要区分为三部分,两个子查询过滤 加上 父查询过滤。
子查询都是走的索引,不涉及全盘扫描,当然本身表数据量也较小,全盘扫描也不一定慢,因此可以排除子查询速度问题
夫查询过滤条件比较有意思,过滤条件全内容为: EXISTS (SELECT 0 FROM "DEPARTMENT" "D" WHERE "D"."ORGID"=3009018715379126415 GROUP BY "D"."L" HAVING "D"."L"=:B1 AND COUNT("D"."L")>1) OR EXISTS (SELECT 0 FROM "DEPARTMENT" "D" WHERE "D"."ORGID"=3009018715379126415 GROUP BY "D"."R" HAVING "D"."R"=:B2 AND COUNT("D"."R")>1)

经过执行器优化后的过滤条件,是将父节点根据 "ORGID"=3009018715379126415 过滤后的结果集依次往 EXISTS中带入依次匹配,如果EXISTS 中带入的是两个子查询查出来的临时表结果,其实也无可厚非,速度也会很快,但看执行计划中的SQL发现,并没有临时表查询操作,或者说压根没有临时表生成,整体还是继续查询Department整张大表,因此上述SQL执行器优化后,实际执行的SQL为:
SELECT * FROM DEPARTMENT pd where pd.ORGID=3009018715379126415 AND
(
EXISTS (SELECT 0 FROM "DEPARTMENT" "D" WHERE "D"."ORGID"=3009018715379126415 GROUP BY "D"."L" HAVING "D"."L"=pd.L AND COUNT("D"."L")>1)
OR EXISTS (SELECT 0 FROM "DEPARTMENT" "D" WHERE "D"."ORGID"=3009018715379126415 GROUP BY "D"."R" HAVING "D"."R"=pd.R AND COUNT("D"."R")>1)
)将执行器优化后的SQL执行一遍,耗时4.8s,可以看到与之前用 IN 写法的SQL耗时一模一样,:
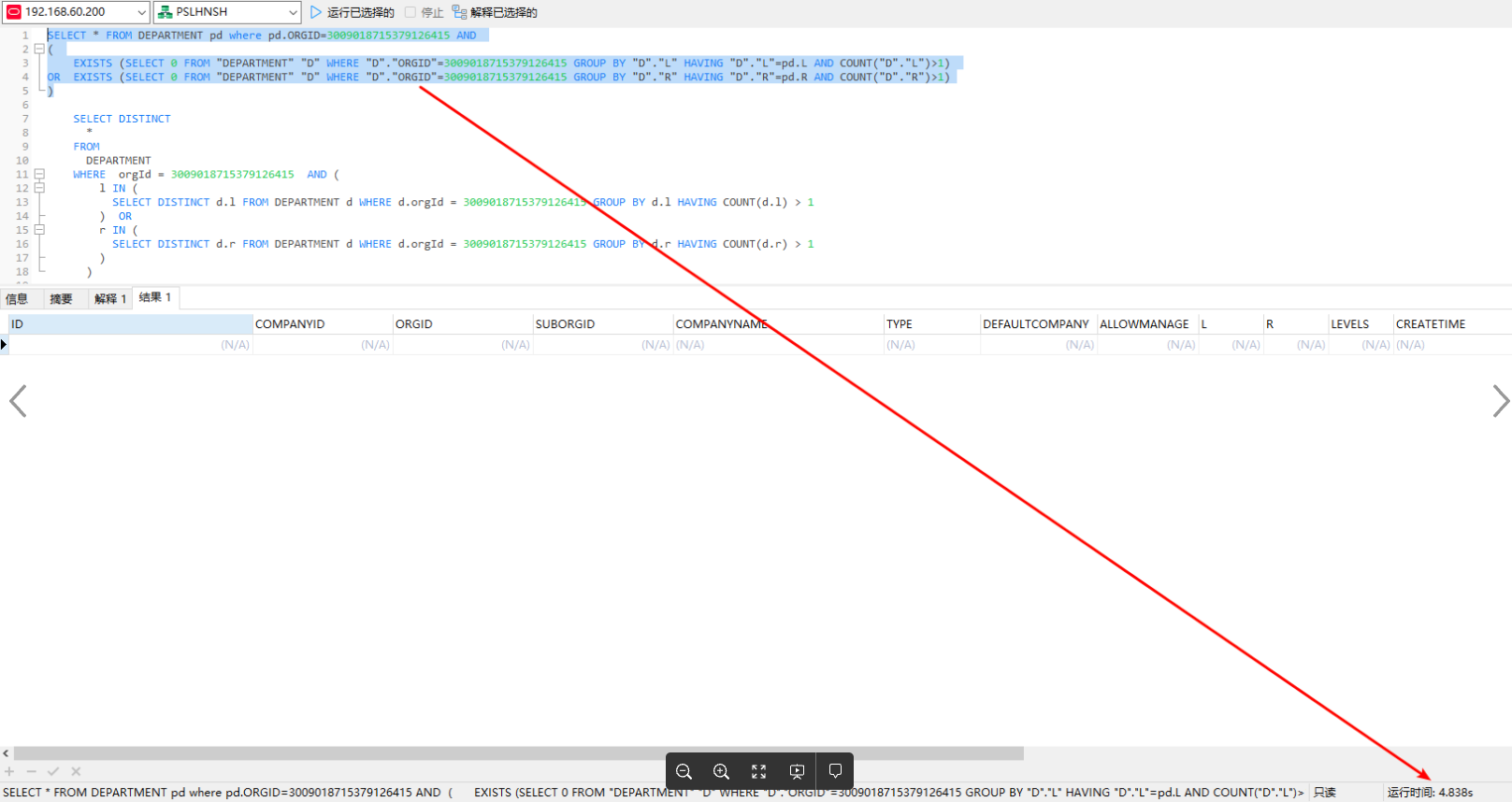
执行计划与原写法执行计划也是一模一样,通过以上可以看出,此SQL在Oracle环境下并不会生成临时表 或 视图,进行子查询过滤,而是替换成了EXIST带入方式,从结果上来看进行了 "反向优化"
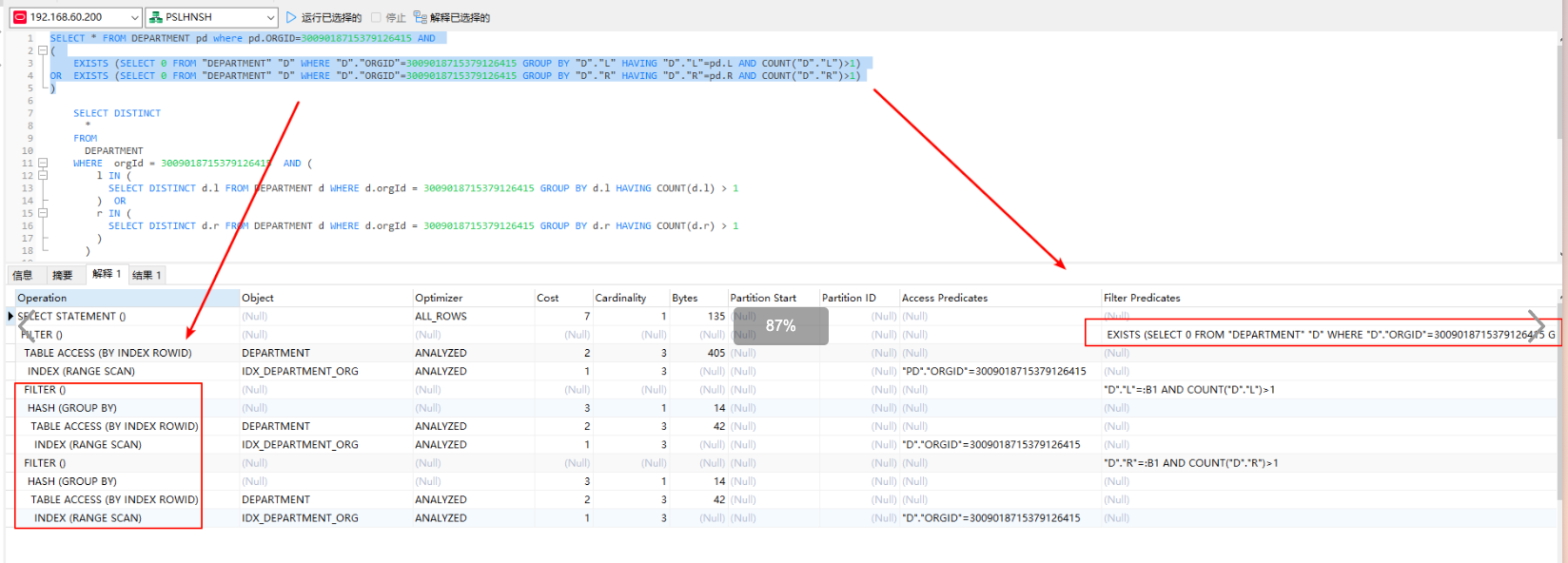
将该SQL带入MySQL数据库中,同数据量下,执行时间只需要0.07s左右,执行计划各项指标表现得也是相当好,从各个方面来看都是一个好SQL,所以再MySQL环境中并没有出现此问题
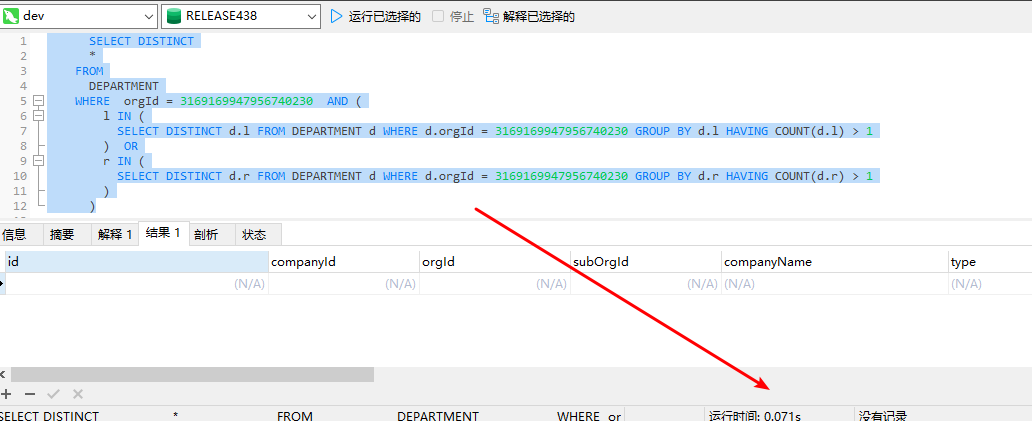

由上可以看出相同SQL对于不同数据库,执行器优化结果可能会存在较大差异,导致相同SQL表现不同性能
分析SQL得知主要是用于查询Department表中相同orgId下有没有相同的 L 或 R 值,因此可以将SQL拆分如下,尽量让每次操作都是简单操作,在将结果联合起来,去除OR的使用,让执行器尽量不走EXIST
select pd.* from DEPARTMENT pd INNER JOIN (SELECT d.l FROM DEPARTMENT d WHERE d.orgId = #{orgId} GROUP BY d.l HAVING COUNT(d.l) > 1)d1 ON pd.l=d1.l WHERE pd.orgId = #{orgId}
UNION
select pd.* from DEPARTMENT pd INNER JOIN (SELECT d.r FROM DEPARTMENT d WHERE d.orgId = #{orgId} GROUP BY d.r HAVING COUNT(d.r) > 1)d2 ON pd.r=d2.r WHERE pd.orgId = #{orgId}
select pd.* from DEPARTMENT pd WHERE pd.orgId = #{orgId} AND pd.l in(SELECT d.l FROM DEPARTMENT d WHERE d.orgId = #{orgId} GROUP BY d.l HAVING COUNT(d.l) > 1)
UNION
select pd.* from DEPARTMENT pd WHERE pd.orgId = #{orgId} AND pd.r in(SELECT d.r FROM DEPARTMENT d WHERE d.orgId = #{orgId} GROUP BY d.r HAVING COUNT(d.r) > 1)第一种与第二种差别只在是否做了内连接,执行计划表现差不多,在Oracle / MySQL下执行计划如下
Oracle:可以清晰看到生成了视图并作过滤,而不是最开的 EXIST 往里带入过滤
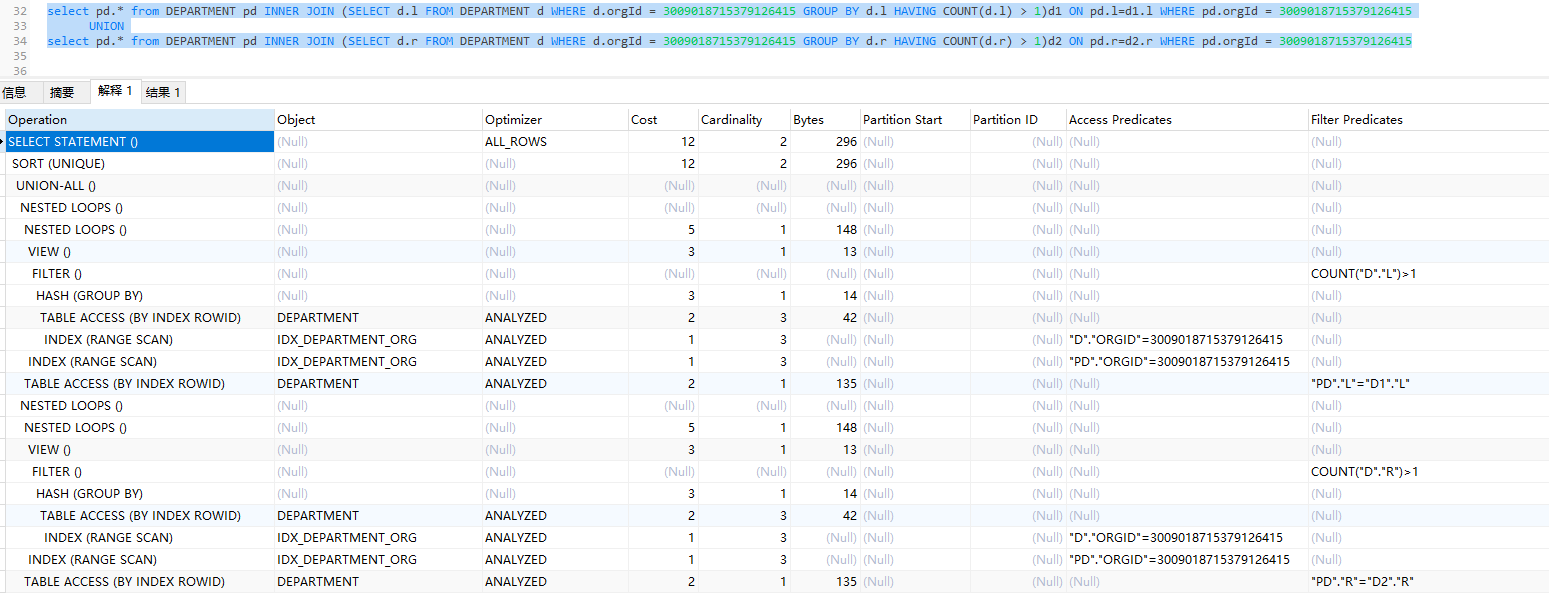
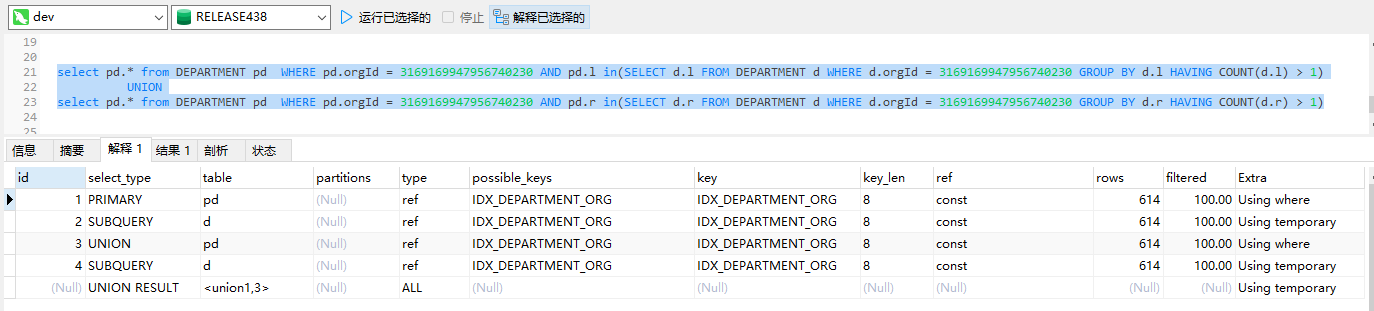
MySQL:可以看到执行计划与原SQL相差无几,只多了一次 UNION的操作,整体指标都是合格指标
评论区